
コンテンツを創造するAI
■現在の人工知能
現在の人工知能研究は第三次人工知能ブームと言われています。ブームと呼ぶ時期はそろそろ過ぎていると言う人もいて、実用化の時代になりつつあるとも考えられています。人工知能を用いることで画像?映像から物を認識したり、音声からの情報を抽出したり、あるいは外国語を日本語に翻訳したり、様々なことができます。こういったことの実現は、機械学習によってもたらされています。
機械学習とは、コンピュータにデータと学習方法を渡して、データが持つ特徴などをとらえることです。その結果、その特徴から未知のデータに対する予測や分類を行うことができるようになります。この「学習方法」として、昨今、主に使われているのが人工ニューラルネットワークです。人工ニューラルネットワークは、人間の脳において脳神経回路網での情報伝達をコンピュータ上に模倣したものです。このニューラルネットワークに入力されるデータを基に算出される出力が正しい結果に近づくように内部パラメータを調整することが学習であり、この学習によって入力データの特徴を獲得します。
現在のニューラルネットワークによる機械学習では、人間の脳神経細胞であるニューロンを単純にコンピュータ上に作り上げるだけでなく、いくつもの新しい技術を組み合わせたものとなっています。画像処理では、畳み込みニューラルネットワークや、それを何層も重ねたディープラーニングなどによって飛躍的に性能が向上しました。また、自然言語処理ではLSTMやGRUを用いたものからトランスフォーマーを用いたものに移り、表現力が格段に向上しています。こういった技術により、ある種の問題に特化したモノについては、人間よりも高い精度で対処できるようになってきています。
さて、第三次人工知能ブームでニューラルネットワークが躍進した理由の一つとして、3DCG処理のためのGPUをニューラルネットワーク処理への転用が挙げられます。これにより、ニューラルネットワークの演算と学習処理は格段と速度が向上しました。また、同時期にGPU自体の性能が向上したため、ニューラルネットワークはますます良い結果を得ることになってきました。こういった中で、ニューラルネットワークはさらに複雑なものが作られるようになり、いわゆるディープラーニングと呼ばれる深いネットワークが構築されて、膨大なパラメータの元、多くのことを学習できるようになってきています。
■人工知能によるコンテンツ生成
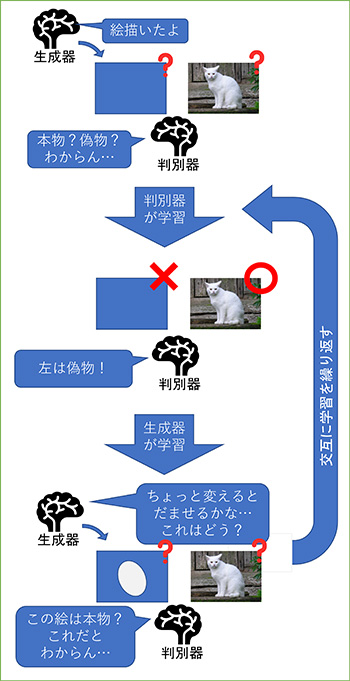
この第三次人工知能ブームの中で発達した技術の一つとして、生成系AIが上げられます。第三次人工知能ブームにおけるニューラルネットワークの活躍は、畳み込みニューラルネットワークとそれを用いたディープラーニングによる画像分類から始まりました。これは、画像がどの分類に該当するかを学習し、また、学習結果から予測するものとなっています。この延長として、画像の中のどこに何が移っているかを認識する物体認識などもでてきました。
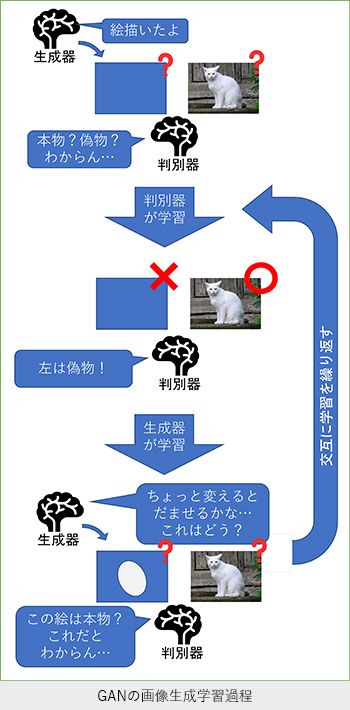
さらに様々な技術が付加された高度なGANで顔画像を生成するサイトをご覧いただくと、どれくらいの画像が生成されるかお分かりいただけるかと思います。このサイト(thispersondoesenotexist.com 外部サイト)は顔画像を生成するサイトです。たまにおかしな画像を生成することもありますが、ほとんどの画像は本物の顔写真と見分けがつきません。
また、生成系AIは、ランダムに画像を生成するだけでなく、既存の画像を変形あるいは合成して新たな画像を生成するものもでてきています。例えば、自動着色技術を使うと、白黒写真をカラー写真にしたり単色の漫画に色を付けたりといったことも自動的に行うことができます。また、カメラ映像や動画に出てくる顔を別人のものに置き換えるといったこともでき、これは、フェイクニュースなど悪用されることもあります。
また、条件に沿った画像を生成するConfidential GANといったものもあり、手書き数字データセットMNISTを用いて学習を行うと、任意の数字を新たな手書き文字で書くといったこともできるようになります。この延長として、文章からその文章の意図を満たす画像を生成するtext-to-imageといった技術も登場してきました。

一方、この第三次人工知能ブームでは自然言語処理分野でも機械学習が著しい発展を遂げています。自然言語処理においても、文章の感情分析のような分類問題に対応するAIも存在しますが、実用的な用途としては機械翻訳やチャットボットのような文章を生成する生成系AIが多数出てきています。
機械翻訳では、もともとGoogle社のGoogle翻訳が一歩先を行っていましたが、DeepL翻訳が登場したときにはGoogle翻訳を上回る翻訳精度として話題になりました。実際,口語や比喩的言い回しが多い文章では、それを直訳してしまうGoogle翻訳より上手に翻訳を行っていました。
こういった自然言語処理への機械学習の応用が進んだのはTransformerと呼ばれる技術が登場したためです。それまでに使われていたLSTM/GRUよりも効果的?効率的に大規模な自然言語データの学習ができることから多くの自然言語処理で使われるようになりました。その中でも、Google社が作成したBERTやOpenAIから発表されたGPT-2,GPT-3は巨大な学習データを膨大な学習パラメータを用いて学習した学習済みモデルであり非常に自然な文章生成が行えるようになってきています。GPT-2を利用した「AIのべりすと」では、数行の文章を記述することで、それ以降の小説を自動的に生成することができます。
また、単に文章を作るだけではなく、対話もできるようになってきており、2022年にOpenAIから発表されたChatGPTは、ベータ版ながら様々な質問に流暢に答えてくれます。例えば、「最近の生成系AIについて教えてください。」と質問すると以下のように返ってきます:
生成系AIは、人間が生成するような文章や画像、音声などを自動的に生成するAI技術です。近年、深層学習を採用することで、より自然で人間に近い生成物を生成することができるようになりました。
いくつか有名な生成系AIを紹介します。
?GPT (Generative Pre-training Transformer):言語生成モデルの代表的なもので、自然言語を生成することができます。GPT-3は、膨大な文章を生成することができる大規模なモデルです。
?GAN (Generative Adversarial Network):画像生成モデルの代表的なもので、人間の目には区別がつかないような写真のような画像を生成することができます。
?WaveNet:音声生成モデルの代表的なもので、人間のような自然な音声を生成することができます。
これらはあくまでも一例であり、現在ではさまざまな生成系AIが開発されています。

■生成系AIの今後
機械学習の世界では、1年単位での飛躍が非常に大きいです。特に最近では、とてつもなく巨大なデータを用いて、今まででは考えられないほど膨大なパラメータで学習を行うことで、格段に精度が上がることがあります。いわゆるGAFAMと呼ばれる巨大IT企業は膨大なデータを持っており、資金力と合わせて、急激な発展が見込まれます。それこそ、今はできないこと、10年後にはと言われていたことが、数か月で出てきても不思議ではない状況です。
一方で、ネットで公開している写真や個人情報が、収集されて使われることが問題となっています。また、生成した著作物の著作権は誰のものかといった問題もまだまだ、議論されている最中です。こういった話が今後どうなるか注目する必要があります。
こうなると、中小企業や大学などの研究機関では開発が追い付かず、人工知能は巨大企業だけが扱えるものになっていくのでしょうか。実際にはそうはならず、少ないデータで効率的な学習を行う研究開発や、オープンになっている巨大なデータ、パラメータをもととしたAIをさらに活用した別の研究開発が進むでしょう。
また、個人での利用についてみてみると、最近ではAI絵師と呼ばれるAI技術を利用してイラストや漫画を発表する人たちも出てきています。これからは、いわゆる画力だけではなく、AIを活用する能力もこういったコンテンツの開発には必要になってくるでしょう。その中で、AIを用いた漫画やアニメがこれまで以上に出現してくるでしょうし、もっと使いやすくなったツールも出てくると考えられます。
また、メディアミックス的な観点からもアニメや漫画作品、そこからゲームを作るだけでなく、関連サービスとして、アニメや漫画のキャラクターといつでも会話できるボットサービスなども出てくることと思います。
■高校生の皆さんへ
高校生の皆さんが、大学生になるころにはもっと状況が変わっていることでしょう。AIは研究室の中に閉じたものではなく、コンテンツに応用される実用的なものになっていきます。また、これまでは、AIが利用されると、そのこと自体が強調されていますが、逆に今後はAIの利用そのものは目立たなくなってくるかもしれません。
人とAIの区別がつかなくなる中で、コンテンツ生成の補助あるいは中核として、AIの活用が進んでいくことになります。AIが発達することにより、コンテンツの作り方、利用方法などが今後変わっていくかもしれません。それでもコンテンツを生み出すのに、人手がいらなくなることはありません。AIとともに新しいコンテンツの制作方法?活用方法が生み出されていくことになります。
このWebページでは、メディア技術コースの藤澤先生にお話をうかがいました。
教員プロフィール
メディア技術コース 藤澤 公也 講師

■私は学生時代に、人工知能によって「パズルをコンピュータに解かせる」という研究から、人工知能の中でもニューラルネットワークについて興味を持ちました。このパズルを解かせる研究を続けて、学位を取りました。メディア学部で働くようになり、一時期は人工知能から離れたこともあったのですが、コンピュータ?GPUの性能向上とともに盛り上がってきた人工知能の研究?教育を行うようになりました。ディープラーニングの発達とともに人工知能はメディア情報処理、とりわけコンテンツ処理で力を発揮するようになってきています。ディープラーニングのコンテンツへの応用的?発展的な研究やそれらを学生の皆さんに伝える授業を行っていきたいと思っています。